Quick start to CMS Open Data
Contents
Quick start to CMS Open Data#
This is a jupyter notebook, where you can have text “cells” (like this text here) and code “cells” i.e. boxes where you can write python code to be executed (like the one below). No need to install anything (if you run this on http://mybinder.org/) or find compilers, it is all done for you in background.
For the exercise with CMS open data, we use python as programming language: it is easy to get started, just type, for example, 1 + 1 in the cell below and click on “Run” icon above.
1+1
2
Now try something more advanced, for example sqrt(4)
sqrt(4)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Input In [2], in <cell line: 1>()
----> 1 sqrt(4)
NameError: name 'sqrt' is not defined
That failed: basic python can do some operations but for anything more complex, we need additional software packages or “modules”.
That’s what we will import here (select the cell below and run it by clicking on the Run icon):
import pandas as pd
#pandas is for data structures and data analysis tools
import numpy as np
#numpy is for scientific computing
import matplotlib.pyplot as plt
#matplotlib is for plotting
Now, you want to try whether sqrt(4) works now? No, it does not… you will have to tell jupyter that you want to take the function from numpy (which for brevity was named np above). So try np.sqrt(4)…
np.sqrt(4)
2.0
Note that you can modify this page at any time, it does no harm. You can add cells (Insert) and change their type from Code (default) to text (i.e. “Markdown”) under Cell -> Cell type.
OK, let’s get started with the data. We’ll read the data from the CERN Open data portal. We call it “data” but you can use any other name.
# we use read_csv function from pandas to read the data into a "data frame"
data = pd.read_csv('http://cern.ch/opendata/record/545/files/Dimuon_DoubleMu.csv')
We’ll have a look what we got in these data:
data.head()
| Run | Event | type1 | E1 | px1 | py1 | pz1 | pt1 | eta1 | phi1 | ... | type2 | E2 | px2 | py2 | pz2 | pt2 | eta2 | phi2 | Q2 | M | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 165617 | 74601703 | G | 9.6987 | -9.5104 | 0.3662 | 1.8633 | 9.5175 | 0.1945 | 3.1031 | ... | G | 9.7633 | 7.3277 | -1.1524 | 6.3473 | 7.4178 | 0.7756 | -0.1560 | 1 | 17.4922 |
| 1 | 165617 | 75100943 | G | 6.2039 | -4.2666 | 0.4565 | -4.4793 | 4.2910 | -0.9121 | 3.0350 | ... | G | 9.6690 | 7.2740 | -2.8211 | -5.7104 | 7.8019 | -0.6786 | -0.3700 | 1 | 11.5534 |
| 2 | 165617 | 75587682 | G | 19.2892 | -4.2121 | -0.6516 | 18.8121 | 4.2622 | 2.1905 | -2.9881 | ... | G | 9.8244 | 4.3439 | -0.4735 | 8.7985 | 4.3697 | 1.4497 | -0.1086 | 1 | 9.1636 |
| 3 | 165617 | 75660978 | G | 7.0427 | -6.3268 | -0.2685 | 3.0802 | 6.3325 | 0.4690 | -3.0992 | ... | G | 5.5857 | 4.4748 | 0.8489 | -3.2319 | 4.5546 | -0.6605 | 0.1875 | 1 | 12.4774 |
| 4 | 165617 | 75947690 | G | 7.2751 | 0.1030 | -5.5331 | -4.7212 | 5.5340 | -0.7736 | -1.5522 | ... | G | 7.3181 | -0.3988 | 6.9408 | 2.2825 | 6.9523 | 0.3227 | 1.6282 | 1 | 14.3159 |
5 rows × 21 columns
This is a dataset from http://opendata.cern.ch/record/545 on CERN Open Data Portal. It is a csv (comma separated values) file which can be easily used in many different frameworks. You can find other files of this type with this search.
What has been written in this dataset are the values (charge, direction, energy, momentum) of two muons from a CMS primary dataset http://opendata.cern.ch/record/17. All other particles have been omitted. If you’re interested, the code and instructions for producing this kind of simplified datasets are in http://opendata.cern.ch/record/552
Now, if you brave enough you can compute the invariant mass for the two muons. If you are in a hurry, just use the value M, which has been computed for you already :-)
invariant_mass = data['M']
You can type the name of your new variable to see what went in there:
invariant_mass
0 17.4922
1 11.5534
2 9.1636
3 12.4774
4 14.3159
...
99995 11.2077
99996 14.5819
99997 29.8425
99998 20.2068
99999 9.3741
Name: M, Length: 100000, dtype: float64
Now let’s make a histogram
# Plot the histogram with the function hist() of the matplotlib.pyplot module:
# (http://matplotlib.org/api/pyplot_api.html?highlight=matplotlib.pyplot.hist#matplotlib.pyplot.hist).
# 'Bins' determines the number of the bins used.
plt.hist(invariant_mass, bins=500)
# Name the axises and give the title.
plt.xlabel('Invariant mass [GeV]')
plt.ylabel('Number of events')
plt.title('The histogram of the invariant masses of two muons \n') # \n creates a new line for making the title look better
# plt.yscale('log')
# Show the plot.
plt.show()
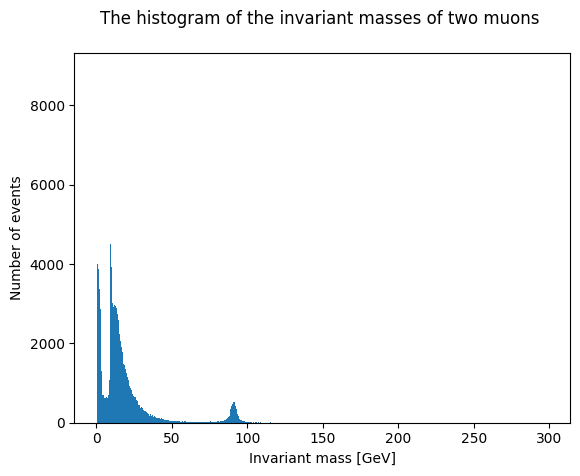
You can check whether log scale looks better. Just edit the cell above, uncomment plt.yscale(‘log’) before plt.show() and run it again.
Now zoom to see whether you can find some familiar particles in the dimuon spectrun. We can do that by setting the range of the histogram with option range=[min,max].
plt.hist(invariant_mass, bins=200, range=[8,12])
plt.show()
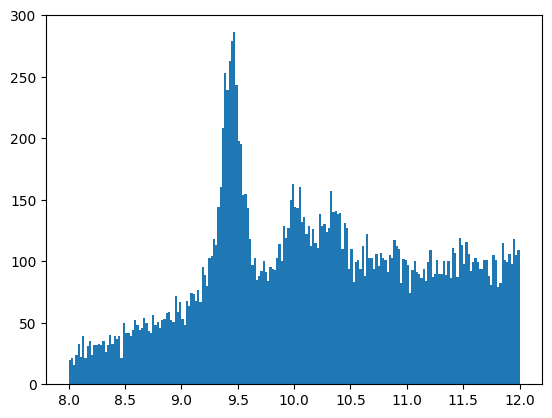
Have a look at the very low invariant mass range as well (change the range limits in the cell above and run it again). You will be surprised to see how well some low mass particles are visible in our data!
We have compiled a list of particles decaying into two muons (extracted for easier reading for educational purposes from C. Patrignani et al. (Particle Data Group), Chin. Phys. C, 40, 100001 (2016) and 2017 update.). In a teaching situation, you can ask students to identify these particles in the plot.
Note that binder does not save your changes. To save your work, download it from File -> Download as -> Notebook. This saves a local copy to your computer (and has no effect on the original notebook).
Some additional material#
If you want to compute yourself the invariant mass from energy and momentum of the two muons, know that you can access the values out of our dataset by data.E1 and data.px1 etc. Remember that before every complex mathematical function you must define that it comes from the numpy package, which we imported and which we defined as np (e.g. np.sqrt(your_value)).
As an extra challenge, note that it happens that one value of the newly computed invariant mass squared goes below 0 (sorry, this is real data) so we will have to exclude that from our set of values before taking the square root… not that nice but a good occasion to show how you can very efficiently set a selection criteria in a dataset with “pandas”
mass_squared = (data.E1 + data.E2)**2 - ((data.px1 + data.px2)**2 +(data.py1 + data.py2)**2 +(data.pz1 + data.pz2)**2)
mass_squared_pos = mass_squared[(mass_squared >0)]
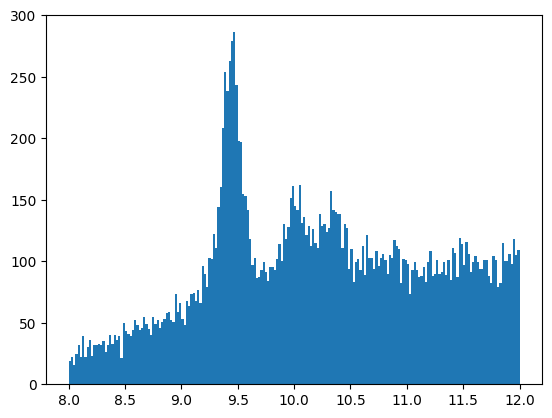
Now plot the invariant mass again to compare it with the histograms above. Did we get it right?
plt.hist(np.sqrt(mass_squared_pos), bins=200, range=[8,12])
plt.show()
For more examples, have a look in https://github.com/cms-opendata-education. You are free to copy and modify these notebooks, and suggest new ones to be added to our collection. This material will also be available through CERN Open Data Portal.