Histogrammi
Contents
Histogrammi#
Eräs erittäin tärkeä työkalu data-analyysiin on histogrammi. Histogrammi on kaavio, jossa on luokiteltu tietyn muuttujan arvoja erikokoisiksi pylväiksi. Luokat määritellään ennen kaavion piirtämistä. Histogrammissa luokat ovat vaaka-akselilla suuruusjärjestyksessä, ja niiden esiintyvyys on pystyakselilla. Pylvään pinta-ala kertoo sen, kuinka suuri osuus datasta kuuluu kyseiseen luokkaan.
Käytetään esimerkkinä NHL-pelaajien pelitietoja. Tiedot ovat peräisin QuantHockey-sivustolta, ja se pitää sisällään tietoa yli 8000:sta pelaajasta.
#Otetaan käyttöön tarvittavat kirjastot.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#Ladataan käytettävä tiedosto muuttujaan.
%matplotlib inline
nhl_data = pd.read_csv("https://raw.githubusercontent.com/opendata-education/Python-ja-Jupyter/main/materiaali/harjoitukset/NHL-players.csv")
nhl_data.head()
| Name | Pos | Birthdate | Birth City | Country | GP | G | A | P | PIM | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Aalto, Antti | F | 03/04/1975 | Lappeenranta | Finland | 151 | 11 | 17 | 28 | 52 |
| 1 | Abbott, George | G | 08/03/1911 | Sydenham, Ontario | Canada | 1 | 0 | 0 | 0 | 0 |
| 2 | Abbott, Reg | F | 02/04/1930 | Winnipeg, Manitoba | Canada | 3 | 0 | 0 | 0 | 0 |
| 3 | Abbott, Spencer | F | 04/30/1988 | Hamilton, Ontario | Canada | 2 | 0 | 0 | 0 | 0 |
| 4 | Abdelkader, Justin | F | 02/25/1987 | Muskegon, Michigan | United States | 739 | 106 | 146 | 252 | 608 |
Haluamme tarkastella pelaajien syntymäkuukausien jakaumaa. Olisiko mahdollista, että joinakin kuukausina syntyneitä pelaajia on selvästi enemmän kuin muina kuukausina syntyneitä?
# Otetaan datasta erikseen syntymäpäivät, ja muutetaan sitä niin, että jäljelle jää vain kuukaudet.
# Tämän kohdan ymmärtäminen ei ole tärkeää kokonaisuuden kannalta.
syntymapaivat = pd.to_datetime(nhl_data['Birthdate'],format='%m/%d/%Y')
kuukaudet = syntymapaivat.dt.month
# Piirretään histogrammi pelaajien syntymäkuukausista
plt.hist(kuukaudet, bins=12)
plt.show()
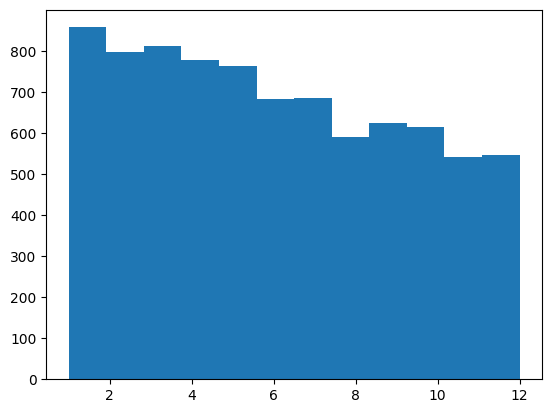
Hienoa, saimme valmiiksi ensimmäisen histogrammin! Voimme halutessamme tehdä siitä kauniimman nimeämällä akselit ja lisäämällä muita selkeyttäviä ominaisuuksia.
fig, ax = plt.subplots() #Talletetaan kuvaaja ja sen akselit muuttujiin
fig.set_figheight(6)
fig.set_figwidth(10) #Asetetaan kuvaajan mitat sopivan kokoisiksi
bins = np.arange(1,14) #Käytetään luokkien määrään numpy-kirjaston arange-funktiota, jotta luokat saadaan oikeille kohdille kuvaajalla.
plt.hist(kuukaudet, bins=bins,edgecolor='k', align='left') #'edgecolor'-muuttujan avulla eri kuukaudet saadaan eroteltua toisistaan. align-muuttujan avulla luokat asetetaan oikeille kohdilleen.
plt.title('NHL-pelaajien syntymäkuukaudet') #Nimetään kuvaaja
plt.xlabel('syntymäkuukausi') #Nimetään x-akseli
plt.ylabel('määrä') #Nimetään y-akseli
plt.show()
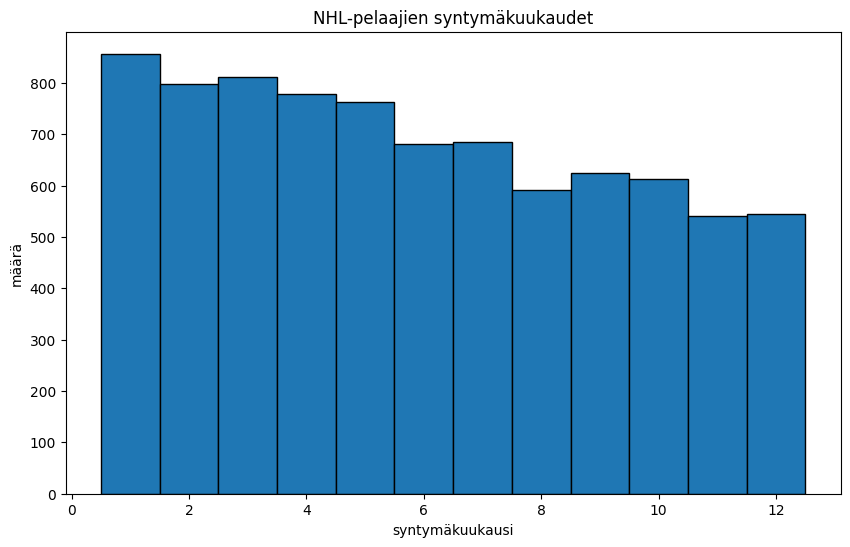
Nyt näyttää jo paremmalta! Muuttamalla binien määrää voimme tehdä uudenlaisia havaintoja. Voi esimerkiksi olla hyödyllistä tarkastella, kuinka suuri osuus pelaajista on syntynyt alku- ja loppuvuonna. Tämä saadaan aikaan vaihtamalla luokkien määräksi kaksi.
fig = plt.figure(figsize=(10,6))
plt.hist(kuukaudet, bins=2,edgecolor='k')
plt.title('NHL-pelaajien syntymäkuukaudet') #Nimetään kuvaaja
plt.xlabel('syntymäkuukausi') #Nimetään x-akseli
plt.ylabel('määrä') #Nimetään y-akseli
plt.show()
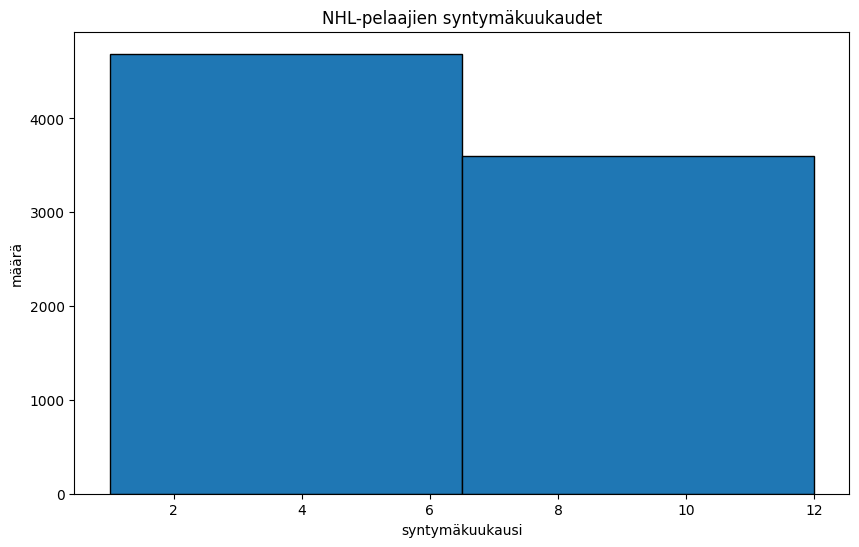
Todetaan, että NHL-pelaajien keskuudessa alkuvuonna syntyneitä on huomattavasti enemmän kuin loppuvuotena syntyneitä. Osaatko sanoa, mistä tämä voisi johtua?
Jos tavoitteenasi oli oppia aivan perusteet histogrammeista, yllä olevan lukeminen on tarpeeksi. Jatka lukemista, jos haluat syventyä vielä lisää histogrammeihin ja niiden ominaisuuksiin.
Ero pylväsdiagrammeihin#
Toinen tärkeä työkalu data-analyysiin on pylväsdiagrammi. On tärkeää osata tunnistaa histogrammin ja pylväsdiagrammin ero. Pylväsdiagrammi eroaa histogrammista siten, että siinä data erotellaan erillisiksi kategorioiksi, joiden välillä ei ole mitään tiettyä järjestystä. Kategoriat muodostavat pylväitä, joiden korkeus kertoo kyseisen kategorian esiintyvyyden. Pylväsdiagrammin esitystapa eroaa histogrammista siten, että pylväät eivät koske toisiaan. Pylväiden järjestystä voi myös siirrellä, sillä niillä ei ole välttämättä tiettyä järjestystä.
Piirretään seuraavaksi pylväsdiagrammi pelaajien kotimaista.
maat = nhl_data['Country'].astype(str) #Talletetaan pelaajien kotimaat muuttujaan.
ax = maat.value_counts().plot(kind='bar', figsize=(14,8), title="Pelaajien lukumäärä maittain") #Piirretään kuvaaja
ax.set_xlabel("Maat") #Nimetään akselit
ax.set_ylabel("Lukumäärä")
plt.show()
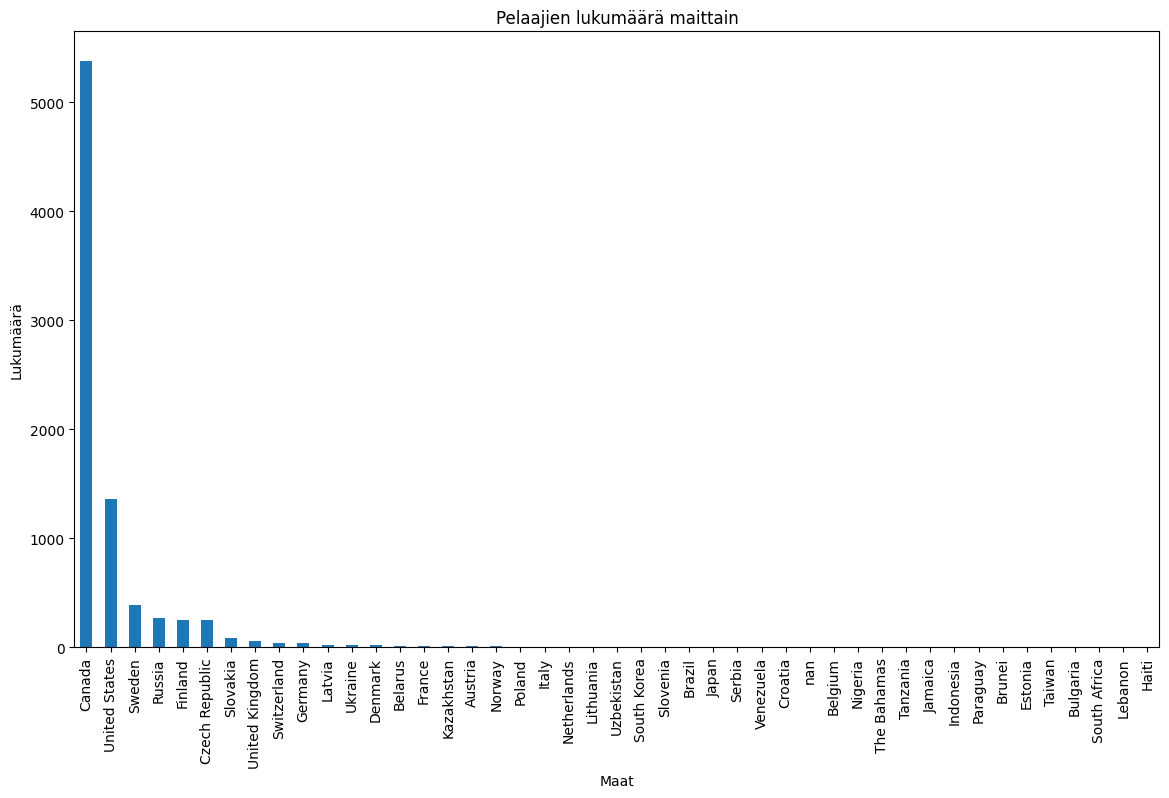
Yllä olevassa kaaviossa maat on jaoteltu sen mukaan, kuinka monta NHL-pelaajaa on sieltä kotoisin. Tämä ei ole kuitenkaan pakollista, ja aivan yhtä hyvin voisimme jaotella maat esimerkiksi aakkosjärjestyksen mukaan.
Jakaumat#
Histogrammien avulla pystytään usein arvioimaan jakaumaan, joka kuvaa muuttujan eri arvojen todennäköisyyttä. Mitä enemmän meillä on dataa, sitä paremmin pystymme arvioimaan jakaumaa. Käytetään esimerkkinä NHL-pelaajien painoja. Tehdään animaatio, jonka avulla näkee, kuinka jakauma muodostuu, kun mittausten määrä kasvaa. Data on kerätty Jatkoaika.com -sivustolta 22.6.2022.
# Talletetaan nykyisten NHL-pelaajien biometrinen data muuttujaan
nhl_biometrics = pd.read_csv("https://raw.githubusercontent.com/opendata-education/Python-ja-Jupyter/main/materiaali/harjoitukset/NHL_biometrics.csv")
nhl_biometrics.head()
| Player | Team | Age | Height (cm) | Weight (kg) | Stick | |
|---|---|---|---|---|---|---|
| 0 | Nick Abruzzese | Toronto | 22 | 178 | 79 | left |
| 1 | Noel Acciari | Florida | 30 | 178 | 95 | right |
| 2 | Sebastian Aho | NY Islanders | 26 | 177 | 83 | left |
| 3 | Sebastian Aho | Carolina | 24 | 183 | 80 | left |
| 4 | Jake Allen | Montreal | 31 | 188 | 86 | left |
painot = nhl_biometrics['Weight (kg)']
# Tuodaan tarvittavat kirjastot
import matplotlib.animation as animation
from scipy.stats import norm
def updt_hist(num, painot):
plt.cla()
plt.xlim((70,120))
plt.hist(painot[:num*10], bins = 50)
plt.gca().set_title('Normaalijakautuman muodostuminen pelaajien painoista')
plt.gca().set_ylabel('määrä')
plt.gca().set_xlabel('paino (kg)')
%%capture
# tämä ns. magic-funktio estää ylimääräisiä frameja ponnahtamasta esiin kesken animaation.
# Alustetaan kuvaaja
fig = plt.figure(figsize=(15,10))
# Luodaan animaatio
anim = animation.FuncAnimation(fig, updt_hist, frames = 100, fargs = (painot,))
#Tehdään animaatiosta HTML-representaatio
from IPython.display import HTML
HTML(anim.to_jshtml())
#Kun olet ajanut tämän solun, scrollaa alaspäin niin näet animaation.
HTML(anim.to_jshtml())
Pelaajien painot näyttävät noudattavan normaalijakaumaa. Normaalijakauma eli Gaussin jakauma esiintyy kaikenlaisissa ilmiöissä ihmisten painoista ja pituuksista hiukkasfysiikkaan. Datamäärän kasvaessa kuvaaja muistuttaa normaalijakaumaa yhä enemmän.
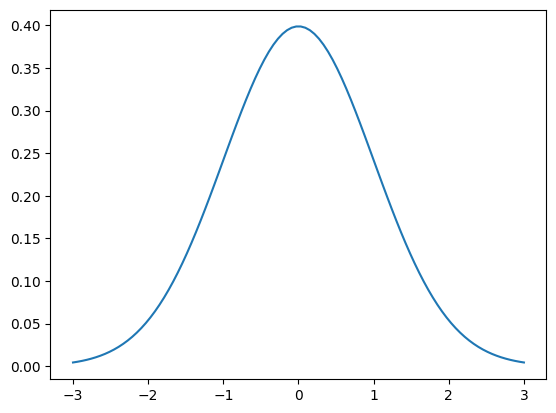
Alla näkyy normaalijakauma keskiarvolla 0 ja keskihajonnalla 1.
import scipy.stats
mu, sigma = scipy.stats.norm.fit(painot)
mu = 0
sigma = 1
x = np.linspace(mu - 3*sigma, mu + 3*sigma, 100)
plt.plot(x, scipy.stats.norm.pdf(x, mu, sigma))
plt.show()
Valinnainen (haastava) lisätehtävä: Sovita normaalijakauma histogrammiin.#
Voit käyttää apunasi tätä materiaalia.
# Kirjoita koodisi alle.