Ohjeita Pythonin käyttöön Jupyterilla
Contents
Ohjeita Pythonin käyttöön Jupyterilla#
Tähän tiedostoon on koottu joitain tärkeimpiä tietoja Pythonin toiminnasta ja erilaisia funktioita joista voi olla hyötyä alkuun pääsemisessä. Mukaan on laitettu muutamia esimerkkejä niiden toiminnasta.
Tämän dokumentin käytöstä: on tarkoituksenmukaista ajaa ensin kohdasta 2 löytyvät paketit ja sitten siirtyä sinne mitä oli etsimässä. Tästä johtuen erinäisiä funktioita, pääasiassa satunnaisgeneraattoreita, määritellään dokumentissa useassa kohtaa edestakaisin selaamisen välttämiseksi.
Jos et muista miten jokin toiminto näissä notebookeissa menikään, paina h-painiketta kun et ole valinnut mitään soluja ja näet listan Jupyterin pikanäppäimistä.
Lähtökohdat
Paketit
Tietorakenteet ja datan käsittely
Peruslaskutoimitukset
Satunnaisdatan luominen
Kuvaajien piirtäminen
Animaatioiden tekeminen
Kartat ja lämpökartat
Ongelmia? Katso tänne
1. Lähtökohdat#
Ohjelmoinnissa muuttujiin voidaan tallentaa erilaisia arvoja, joita halutaan käyttää tai muuttaa myöhemmin. Erilaisia muuttujatyyppejä ovat esimerkiksi kokonaisluku (int), liukuluku (float) ja merkkijono (string). Pythonissa muuttujien luominen on helppoa, sillä muuttujatyyppiä ei tarvitse erikseen määrittää.
Joskus ohjelmaa ajavaan ytimeen, kerneliin, jää muistiin palasia jotka haittaavat ohjelman toimintaa. Tätä sattuu aina välillä, ei hätää. Paina ylävalikoista ‘Kernel’ ja ‘Restart & Clear Output’, jolloin muistissa olevat prosessit ja tulosteet pyyhitään ja voit aloittaa alusta. Tämä ei kuitenkaan vaikuta mihinkään muutoksiin tekstissä tai koodissa, eli se ei ole virheiden korjausnappi.
2. Paketit#
Python on tieteelliseen laskentaan soveltuva ohjelmointikieli, jolle on kehitetty monenlaisia eri tavalla suoritusteholtaan optimoituja toimintoja. Sen perusperiaatteisiin kuuluu erilaisten pakettien, eli funktiokirjastojen, käyttäminen. Nämä paketit tuodaan import-komennolla käyttöön ja vaikka se saattaakin alkuun tuntua hienoiselta taikatempulta tietää mitä pitäisi kutsua, se selkeytyy nopeasti.
Jos vilkaiset Open Data -projektissa tarjottuja materiaaleja, huomaat että jokaisessa Github-kansiossamme on mukana tekstitiedosto “requirements.txt”, jonka mukaan esimerkiksi MyBinder osaa rakentaa Jupyterille työalustan. Sieltä näkee, että tärkeimmät paketit joita tulemme käyttämään ovat seuraavat:
# Oleellisimmat paketit:
import pandas as pd # sisältää erilaisia datan lukemiseen liittyviä työkaluja
import numpy as np # sisältää erilaisia numeerisen laskennan työkaluja
import matplotlib.pyplot as plt # sisältää kuvaajien (plot) piirtotyökaluja
# Muita hyödyllisiä paketteja:
import random as rand # sisältää funktioita satunnaislukujen generoimiseen
from scipy import stats # sisältää tieteellistä laskentaa ja tilastolaskentaa
from scipy.stats import norm # normaalijakaumatyökaluja
import matplotlib.mlab as mlab # lisää kuvaajatyökaluja monimutkaisempiin kuvaajiin
# Ei paketti, mutta oleellinen komento joka mahdollistaa tulosten näkymisen nätisti harjoitteissa:
%matplotlib inline
Muista ajaa yllä oleva solu jos haluat että tämän notebookin esimerkit toimivat. Ylläolevan voisi kirjoittaa lyhemminkin ilman as-merkintää, joka nimeää paketit uudelleen, mutta sillä voidaan merkittävästi lyhentää tulevien solujen tekstejä. Jos haluat lukea paketeista tarkemmin, valitse ylempää pudotusvalikko ‘Help’ ja löydät sieltä linkkejä tarkempiin dokumentaatioihin tai muotoiluohjeisiin.
Paketteja on paljon muitakin ja niitä voi tarpeen mukaan googlailla lisää, jos johonkin tarvitsee. Pythonin laajan käyttäjäkunnan ansiosta verkosta löytää helposti tuhansittain esimerkkejä ja hakemistoja. StackExchange ja StackOverflow ovat hyviä paikkoja vastausten etsimiseen.
3. Tietorakenteet ja datan käsittely#
Kooste:
Csv-luku \(\rightarrow\)
nimi = pd.read_csv('polku', muotoiluargumentteja)
Taulukon luku \(\rightarrow\)
pd.read_table('polku', muotoiluargumentteja)
Sisällön tarkastelu \(\rightarrow\)
nimi.head(n)
Pituus \(\rightarrow\)
len(nimi)
Muoto \(\rightarrow\)
nimi.shape
Sarakkeet \(\rightarrow\)
nimi.sarake
nimi['sarake']
Tietyn välin rajaus \(\rightarrow\)
nimi[(nimi.arvosarake >= alaraja) & (nimi.arvosarake <= yläraja)]
Tekstin etsintä \(\rightarrow\)
vanhaNimi['sarake'].str.contains('haettu_pätkä')
Lisää sarake \(\rightarrow\)
nimi = nimi.assign(sarake = tiedot)
Poista sarakkeita \(\rightarrow\)
nimi.drop(['sarake1','sarake2'...], axis = 1)
CMS-kokeen avoin data on .csv-muotoista, eli pilkuilla erotettua tekstipuuroa (comma separated values). Tällainen tieto on hyvin helppoa lukea taulukkona tietokoneen käyttöön pandas-paketin avulla, jolloin koneen muistiin syntyy kaksiulotteinen ns. dataframe-muotoinen taulukko. Tarkempia tietoja täällä, mistä löytyy myös yksityiskohtaisempi lista eri toiminnoista joita valitulle datalle voi tehdä.
Helpoimmat tavat lukea data käyttöön ovat pd.read_csv ja pd.read_table. Jos data on nättiä (erottajana pilkku, otsikointi on tehty, fontit eivät sodi tervettä järkeä vastaan…), yleensä mitään lisätoimenpiteitä ei tarvita.
# Ladataan setti hiukkasdataa muuttujaksi ja määritetään sille haluttu nimi:
kaksoismyonit = pd.read_csv('../Data/Dimuon_DoubleMu.csv')
# Jos haluaisi käyttää suoraa urlia, sijoita tämä 'http://opendata.cern.ch/record/545/files/Dimuon_DoubleMu.csv'
# nimen tilalle.
Tällainen suora muoto hakee tiedoston, joka sijaitsee samassa kansiossa kuin käytössä oleva notebook. Tiedosto voidaan hakea myös suoraan verkko-osoitteen urlista tai toisesta kansiosta ‘../kansio/tiedosto.csv’ -rakenteella.
Mikäli data on toisessa tekstimuodossa, voi kokeilla yleisempää read_table -käskyä, joka ymmärtää muitakin taulukoitavia tekstejä. Yleisin ongelma on, että teksti on eroteltu jollain muulla kuin pilkulla, kuten tabulaattorilla tai puolipisteellä. Tällöin komentoon voi laittaa argumentin sep = ‘x’, missä x on erottimena käytetty merkki. Toinen yleinen ongelma on, että tiedoston rivitys alkaa omituisesti tai sarakkeiden otsikot ovat jossain muualla kuin ensimmäisellä rivillä. Tällöin voidaan laittaa komentoon argumentti header = n, missä n on otsikoiksi halutun rivin järjestysnumero. HUOM! Tietokone aloittaa järjestysluvut aina nollasta jollei toisin mainita.
Tarkempia tietoja mahdollisista argumenteista täällä.
Alla esimerkki datasta, jolla ei ole otsikkoriviä. Datassa näkyy Auringosta tehtyjä havaintoja vuodesta 1992 eteenpäin ja tarkemmat selosteet kunkin sarakkeen merkityksille löytyvät täältä.
# Ladataan setti aurinkodataa ja nimetään se halutulla tavalla:
aurinko = pd.read_table('http://sidc.oma.be/silso/INFO/sndhemcsv.php', sep = ';', encoding = "ISO-8859-1")
Selkeyden vuoksi katsotaan miltä datamme näyttävät. Tähän sopii erinomaisesti nimi.head(n)-komento, joka näyttää n ensimmäistä riviä valitusta datasta. Oletusarvoisesti n = 5, jos laittaa tyhjät sulkeet.
kaksoismyonit.head()
| Run | Event | type1 | E1 | px1 | py1 | pz1 | pt1 | eta1 | phi1 | ... | type2 | E2 | px2 | py2 | pz2 | pt2 | eta2 | phi2 | Q2 | M | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 165617 | 74601703 | G | 9.6987 | -9.5104 | 0.3662 | 1.8633 | 9.5175 | 0.1945 | 3.1031 | ... | G | 9.7633 | 7.3277 | -1.1524 | 6.3473 | 7.4178 | 0.7756 | -0.1560 | 1 | 17.4922 |
| 1 | 165617 | 75100943 | G | 6.2039 | -4.2666 | 0.4565 | -4.4793 | 4.2910 | -0.9121 | 3.0350 | ... | G | 9.6690 | 7.2740 | -2.8211 | -5.7104 | 7.8019 | -0.6786 | -0.3700 | 1 | 11.5534 |
| 2 | 165617 | 75587682 | G | 19.2892 | -4.2121 | -0.6516 | 18.8121 | 4.2622 | 2.1905 | -2.9881 | ... | G | 9.8244 | 4.3439 | -0.4735 | 8.7985 | 4.3697 | 1.4497 | -0.1086 | 1 | 9.1636 |
| 3 | 165617 | 75660978 | G | 7.0427 | -6.3268 | -0.2685 | 3.0802 | 6.3325 | 0.4690 | -3.0992 | ... | G | 5.5857 | 4.4748 | 0.8489 | -3.2319 | 4.5546 | -0.6605 | 0.1875 | 1 | 12.4774 |
| 4 | 165617 | 75947690 | G | 7.2751 | 0.1030 | -5.5331 | -4.7212 | 5.5340 | -0.7736 | -1.5522 | ... | G | 7.3181 | -0.3988 | 6.9408 | 2.2825 | 6.9523 | 0.3227 | 1.6282 | 1 | 14.3159 |
5 rows × 21 columns
aurinko.head()
| 1992 | 01 | 01.1 | 1992.001 | 186 | 0 | 186 | 14.3 | 1.0 | 14.3 | 19 | -1 | -1.1 | 1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1992 | 1 | 2 | 1992.004 | 190 | 18 | 172 | 8.2 | 2.6 | 7.8 | 21 | -1 | -1 | 1 |
| 1 | 1992 | 1 | 3 | 1992.007 | 234 | 26 | 208 | 18.3 | 6.1 | 17.2 | 21 | -1 | -1 | 1 |
| 2 | 1992 | 1 | 4 | 1992.010 | 243 | 54 | 189 | 14.8 | 7.0 | 13.0 | 20 | -1 | -1 | 1 |
| 3 | 1992 | 1 | 5 | 1992.012 | 242 | 58 | 184 | 13.8 | 6.8 | 12.0 | 18 | -1 | -1 | 1 |
| 4 | 1992 | 1 | 6 | 1992.015 | 245 | 79 | 166 | 18.7 | 10.6 | 15.4 | 14 | -1 | -1 | 1 |
Ylläolevista nähdään, että aurinko-muuttujan ensimmäinen oikea rivi on kaapattu otsikoiksi, mikä on sikäli ikävää että 1) nyt otsikot ovat hämääviä ja 2) meiltä jää yhden rivin verran dataa käsittelemättä jos haluamme vaikkapa kuvaajan taulukon jostain sarakkeesta. Ratkaistaan asia laittamalla dataa ladattaessa otsikointiargumentiksi header = -1, eli rivi jota ei ole olemassa, jolloin kone tuottaa siihen järjestyslukurivin.
aurinko = pd.read_table('http://sidc.oma.be/silso/INFO/sndhemcsv.php', sep = ';', encoding = "ISO-8859-1", header = None)
aurinko.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1992 | 1 | 1 | 1992.001 | 186 | 0 | 186 | 14.3 | 1.0 | 14.3 | 19 | -1 | -1 | 1 |
| 1 | 1992 | 1 | 2 | 1992.004 | 190 | 18 | 172 | 8.2 | 2.6 | 7.8 | 21 | -1 | -1 | 1 |
| 2 | 1992 | 1 | 3 | 1992.007 | 234 | 26 | 208 | 18.3 | 6.1 | 17.2 | 21 | -1 | -1 | 1 |
| 3 | 1992 | 1 | 4 | 1992.010 | 243 | 54 | 189 | 14.8 | 7.0 | 13.0 | 20 | -1 | -1 | 1 |
| 4 | 1992 | 1 | 5 | 1992.012 | 242 | 58 | 184 | 13.8 | 6.8 | 12.0 | 18 | -1 | -1 | 1 |
Jos haluamme muuttaa otsikoinnin selkeämmäksi, voimme tietysti myös nimetä sarakkeet names = [‘nimi’,’nimi2’,’nimi3’]-argumentilla.
aurinko = pd.read_table('http://sidc.oma.be/silso/INFO/sndhemcsv.php', sep=';', encoding = "ISO-8859-1", header = None,
names = ['Vuosi','Kuukausi','Päivä','Fraktio','$P_{tot}$','$P_{poh}$','$P_{et}$','$\sigma_{tot}$','$\sigma_{poh}$',
'$\sigma_{et}$','$N_{tot}$','$N_{poh}$','$N_{et}$','Prov'])
aurinko.head()
| Vuosi | Kuukausi | Päivä | Fraktio | $P_{tot}$ | $P_{poh}$ | $P_{et}$ | $\sigma_{tot}$ | $\sigma_{poh}$ | $\sigma_{et}$ | $N_{tot}$ | $N_{poh}$ | $N_{et}$ | Prov | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1992 | 1 | 1 | 1992.001 | 186 | 0 | 186 | 14.3 | 1.0 | 14.3 | 19 | -1 | -1 | 1 |
| 1 | 1992 | 1 | 2 | 1992.004 | 190 | 18 | 172 | 8.2 | 2.6 | 7.8 | 21 | -1 | -1 | 1 |
| 2 | 1992 | 1 | 3 | 1992.007 | 234 | 26 | 208 | 18.3 | 6.1 | 17.2 | 21 | -1 | -1 | 1 |
| 3 | 1992 | 1 | 4 | 1992.010 | 243 | 54 | 189 | 14.8 | 7.0 | 13.0 | 20 | -1 | -1 | 1 |
| 4 | 1992 | 1 | 5 | 1992.012 | 242 | 58 | 184 | 13.8 | 6.8 | 12.0 | 18 | -1 | -1 | 1 |
nimi.heads()-komennon ohella pari muuta pikkukomentoa ovat hyödyllisiä tarkasteltaessa datan muotoa. len(nimi) kertoo rivien määrän eli muuttujan pituuden (length), nimi.shape sekä rivien että sarakkeiden määrän.
# Normaalisti koodisolun tuloste näyttää vain viimeisimmän annetun toiminnon. Print()-komennolla saadaan
# useampia arvoja näkyviin. Voit kokeilla mitä käy jos poistat printin näiden edestä.
print (len(aurinko))
print (aurinko.shape)
11170
(11170, 14)
Kun data on nyt saatu tyydyttävässä muodossa koneelle, sitä voidaan ryhtyä muokkaamaan halutun näköiseksi. Usein ollaan kiinnostuneita jostain yksittäisestä muuttujasta datan sisässä, jolloin pitää pystyä eristämään tiettyjä sarakkeita alkuperäisistä tiedoista tai valita vain ne rivit, joilla jonkin muuttujan arvo on tietyissä rajoissa.
Sarakkeen voi valita kirjoittamalla nimi.sarake tai nimi[‘sarake’]. Hakasulkumuoto on tarpeen, jos sarakkeen nimi esimerkiksi alkaa numerolla, jonka kone saattaa tulkata järjestysluvuksi. Jos haluaa helpottaa elämäänsä eikä välitä muista sarakkeista, kannattaa tämä eristys tehdä uuteen muuttujaan, eli kirjoittaa uusiNimi = nimi.sarake ja käsitellä sitä. Tässä on sekin etu, että dataa on tällöin vähemmän kerrallaan käsittelyssä eikä tietokone mahdollisten kirjoitusvirheiden tapauksessa ala esimerkiksi piirtämään histogrammeja kymmenissä ulottuvuuksissa koko alkuperäisestä datasta ja tukehdu yrittäessään.
# Erotellaan uuteen muuttujaan myonidatan invarianttien massojen sarake, joka on otsikoitu nimellä M.
iMassat = kaksoismyonit.M
iMassat.head()
0 17.4922
1 11.5534
2 9.1636
3 12.4774
4 14.3159
Name: M, dtype: float64
Rivien valinta tapahtuu luomalla vastaavasti uusi muuttuja, jonka alkioiksi valitaan ne alkuperäisen datan alkiot, jotka täyttävät annetut ehdot. Tällöin esimerkiksi jonkin arvovälin valinta olisi
uusiNimi = nimi[(nimi.arvosarake >= alaraja) & (nimi.arvosarake <= ylaraja)]
Sinänsä jakoehto voi olla mikä tahansa muukin looginen elementti, kuten tasan tietty luku tai tekstinpätkä ei-numeerisessa datassa.
# Otetaan esimerkkinä hiukkasdatasta ne rivit, joissa molempien hiukkasten energia on 30 GeViä tai yli.
yli30 = kaksoismyonit[(kaksoismyonit.E1 >= 30) & (kaksoismyonit.E2 >= 30)]
yli30.head()
| Run | Event | type1 | E1 | px1 | py1 | pz1 | pt1 | eta1 | phi1 | ... | type2 | E2 | px2 | py2 | pz2 | pt2 | eta2 | phi2 | Q2 | M | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21 | 165617 | 74969122 | G | 59.9226 | -46.1516 | 29.4115 | -24.4070 | 54.7266 | -0.4324 | 2.5742 | ... | G | 52.4465 | 30.1097 | -16.3989 | -39.6876 | 34.2859 | -0.9885 | -0.4987 | -1 | 89.9557 |
| 36 | 165617 | 75138253 | G | 97.1011 | -23.6144 | 6.6660 | -93.9497 | 24.5372 | -2.0524 | 2.8665 | ... | G | 30.5992 | -11.6134 | -25.9848 | 11.2347 | 28.4619 | 0.3851 | -1.9911 | 1 | 88.6081 |
| 46 | 165617 | 75887636 | G | 152.9720 | 7.4657 | -30.7098 | -149.6710 | 31.6042 | -2.2593 | -1.3323 | ... | G | 33.5835 | -9.2878 | 28.7457 | -14.6719 | 30.2089 | -0.4684 | 1.8833 | 1 | 88.2438 |
| 78 | 165617 | 75833588 | G | 181.8770 | 44.1427 | -14.9498 | 175.8040 | 46.6055 | 2.0379 | -0.3265 | ... | G | 170.0210 | -34.6301 | 12.3248 | 166.0000 | 36.7579 | 2.2128 | 2.7997 | -1 | 83.0943 |
| 110 | 165617 | 75779415 | G | 50.2440 | 37.8072 | -12.2044 | -30.7590 | 39.7283 | -0.7124 | -0.3122 | ... | G | 49.2396 | -47.6064 | 8.2338 | -9.5061 | 48.3132 | -0.1955 | 2.9703 | -1 | 90.3544 |
5 rows × 21 columns
print (len(yli30))
print (len(kaksoismyonit))
6516
100000
Jos halutaan useampi kokonainen sarake erittelemättä rivejä, voi kirjoittaa
uusiMuuttuja = vanhaMuuttuja[['sarake1', 'sarake2', ...]]
Jos halutaan hakea tekstiä, voidaan kirjoittaa vaikkapa seuraavasti nimi.loc[ ]-funktion avulla.
uusiMuuttuja = vanhaMuuttuja.loc[vanhaMuuttuja['sarake'] == 'haluttu_asia']
Tällöin toki on tiedettävä tarkkaan mitä etsii. Jos haluaa kysyä datalta sokeammin kysymyksiä, contains-toiminto auttaa.
uusiNimi = vanhaNimi[vanhaNimi['sarake'].str.contains('haettu_pätkä')]
tekee uuden muuttujan, jossa on nyt haetun pätkän sisältäneet rivit. Oletusarvoisesti toiminto välittää kirjainkoosta, mutta sen voi laittaa pois päältä kirjoittamalla
uusiNimi = vanhaNimi[vanhaNimi['sarake'].str.contains('haettu_pätkä', case = False)]
Kannattaa huomata, että str.contains() itsessään on looginen operaatio, joten koodi palauttaa tiedon kyllä / ei kysytystä asiasta. Myös negaatio toimii, kuten alla suomalaisten alkoholivalmistajien listan selaaminen poistamalla kaikki Oy tai Oyj yritykset. Samalla toki voi mennä joku Oy-alkuinen firma, joten kannattaa olla tarkkana.
juomat = pd.read_csv('http://avoindata.valvira.fi/alkoholi/alkoholilupa_valmistus.csv', sep = ';', encoding = "ISO-8859-1", na_filter = False)
juomat.head()
| Y-Tunnus | Nimi | Luvan alkupvm | Olut | Viini | Hedelmäviini | Tislatut alkoholijuomat | Väkiviina | Käsityöläisoluen vähittäismyyntilupa | Tilaviinin vähittäismyyntilupa | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0107011-5 | Berner Oy | 03.02.2014 | X | ||||||
| 1 | 0170318-9 | Olvi Oyj | 17.02.1995 | X | X | X | ||||
| 2 | 0171079-2 | Alahovin Viinitila Oy | 25.02.1995 | X | X | X | X | X | ||
| 3 | 0171110-3 | Oy Gust. Ranin Lignell & Piispanen | 20.01.1995 | X | X | |||||
| 4 | 0193088-3 | Kakslauttanen Arctic Resort Oy | 25.02.2020 | X |
tiettyValmistaja = juomat[juomat['Nimi'].str.contains('Oy') == False]
print (len(juomat))
print (len(tiettyValmistaja))
204
35
Jos haluat lisätä tai poistaa sarakkeita datasta, siihen sopivat toiminnot nimi = nimi.assign(sarake = tiedot) ja nimi.drop([‘sarake1’,’sarake2’…], axis = 1). Dropissa axis on sikäli tärkeä parametri, että komento ymmärtää poimia nimenomaan sarakkeen.
# Sarakkeen poistaminen dropilla.
# Joskus .drop ei toimi suoraan, joten tallennetaan sen tulos aiemman muuttujan tilalle sekaannuksen välttämiseksi.
juomat = juomat.drop(['Nimi'], axis = 1)
juomat.head()
| Y-Tunnus | Luvan alkupvm | Olut | Viini | Hedelmäviini | Tislatut alkoholijuomat | Väkiviina | Käsityöläisoluen vähittäismyyntilupa | Tilaviinin vähittäismyyntilupa | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0107011-5 | 03.02.2014 | X | ||||||
| 1 | 0170318-9 | 17.02.1995 | X | X | X | ||||
| 2 | 0171079-2 | 25.02.1995 | X | X | X | X | X | ||
| 3 | 0171110-3 | 20.01.1995 | X | X | |||||
| 4 | 0193088-3 | 25.02.2020 | X |
# Sarakkeen lisääminen assignilla.
# Laitetaan tässä äskeiseen mukaan sarake R, jossa on numeroita.
# Huolehdi, että sarake on oikean mittainen. Sisältö itsessään voi olla mitä vain, lukuja, tekstiä jne.
luvut = np.linspace(0, 100, len(juomat))
juomat = juomat.assign(R = luvut)
juomat.head()
| Y-Tunnus | Luvan alkupvm | Olut | Viini | Hedelmäviini | Tislatut alkoholijuomat | Väkiviina | Käsityöläisoluen vähittäismyyntilupa | Tilaviinin vähittäismyyntilupa | R | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0107011-5 | 03.02.2014 | X | 0.000000 | ||||||
| 1 | 0170318-9 | 17.02.1995 | X | X | X | 0.492611 | ||||
| 2 | 0171079-2 | 25.02.1995 | X | X | X | X | X | 0.985222 | ||
| 3 | 0171110-3 | 20.01.1995 | X | X | 1.477833 | |||||
| 4 | 0193088-3 | 25.02.2020 | X | 1.970443 |
4. Peruslaskutoimitukset ja syntaksilogiikka#
Kooste:
Itseisarvot \(\rightarrow\)
abs(x)
Neliöjuuret \(\rightarrow\)
sqrt(x)
Yhteenlasku \(\rightarrow\)
x + y
Vähennyslasku \(\rightarrow\)
x - y
Jakolasku \(\rightarrow\)
x/y
Kertolasku \(\rightarrow\)
x*y
Potenssit \(\rightarrow\)
x**y
Suurin arvo \(\rightarrow\)
max(x)
Pienin arvo \(\rightarrow\)
min(x)
Oman funktion luominen \(\rightarrow\)
def nimi(syöte):
toimitukset
Peruslaskutoimituksissa ei ole mitään erityisen ihmeellistä, ne kirjoitetaan siinä missä mihin tahansa muuhunkin tietokonelaskimeen. Jos haluaa ohjelman tulostavan useamman asian kerrallaan, kannattaa käyttää print()-komentoa jolloin muutakin kuin viimeisin vaihe tulee näkyviin. Tekstiä ja numeroita voi myös yhdistää, jolloin repr(lukuja) voi helpottaa. Tämä näppärä funktio palauttaa annetusta muuttujasta printattavan version. Tästä näppärästä listasta näkee mitä kaikkia sisäänrakennettuja funktioita Pythonissa on ilman pakettejakin, mm. pienimmän ja suurimman luvun etsimistä tiedostosta, lukujen pyöristämistä ja vastaavaa. Jos joku jäi ihmetyttämään, tässä vielä lisää samasta asiasta.
# Voit muokata 'luku'-muuttujan sisältöä eri laskuiksi.
luku = 14*2+5/2
teksti = 'Päivän tulos on: '
print (teksti + repr(luku))
Päivän tulos on: 30.5
# Max() hakee joukon suurimman alkion.
kasaLukuja = [3,6,12,67,578,2,5,12,-34]
print('Suurin luku on ' + repr(max(kasaLukuja)))
Suurin luku on 578
Kiinnostavampaa on, että Pythonissa voi luoda myös omia funktioitaan tiettyihin tarpeisiin. Tällöin määritellään funktion nimi ja vaikutus sisään laitettuun tietoon kirjoittamalla
def funktionNimi(syöte):
kuvaus sisennettynä
# Luodaan funktio, joka puolittaa sille syötetyn numeron.
def puolitus(a):
print(a/2)
puolitus(6)
3.0
# Tehdään summauskone, joka kysyy käyttäjältä kokonaislukuja (toimii MyBinderissa).
def summaus(x, y):
summa = x + y
lause = '{} + {} on yhteensä {}.'.format(x, y, summa)
print(lause)
def vapaaValinta():
a = int(input("Anna kokonaisluku: "))
b = int(input("Anna toinenkin kokonaisluku: "))
summaus(a, b)
vapaaValinta()
---------------------------------------------------------------------------
StdinNotImplementedError Traceback (most recent call last)
Input In [24], in <cell line: 13>()
10 b = int(input("Anna toinenkin kokonaisluku: "))
11 summaus(a, b)
---> 13 vapaaValinta()
Input In [24], in vapaaValinta()
8 def vapaaValinta():
----> 9 a = int(input("Anna kokonaisluku: "))
10 b = int(input("Anna toinenkin kokonaisluku: "))
11 summaus(a, b)
File /opt/hostedtoolcache/Python/3.8.13/x64/lib/python3.8/site-packages/ipykernel/kernelbase.py:1174, in Kernel.raw_input(self, prompt)
1167 """Forward raw_input to frontends
1168
1169 Raises
1170 ------
1171 StdinNotImplementedError if active frontend doesn't support stdin.
1172 """
1173 if not self._allow_stdin:
-> 1174 raise StdinNotImplementedError(
1175 "raw_input was called, but this frontend does not support input requests."
1176 )
1177 return self._input_request(
1178 str(prompt),
1179 self._parent_ident["shell"],
1180 self.get_parent("shell"),
1181 password=False,
1182 )
StdinNotImplementedError: raw_input was called, but this frontend does not support input requests.
# Luodaan funktio, joka palauttaa annetun radiaanilistan tulokset astelistana. While-silmukka käy läpi ensimmäisestä
# alkiosta haluttuun kohtaan asti listaa ja tekee alkioille jonkun toimituksen.
def kulmaus(a):
i=0
while i < len(a):
a[i] = a[i]*360/(2*np.pi)
i+=1
return a;
radeja = [5,2,4,2,1,3]
kulmaus(radeja)
print(radeja)
[286.4788975654116, 114.59155902616465, 229.1831180523293, 114.59155902616465, 57.29577951308232, 171.88733853924697]
# Tai sama nätimmin for-silmukkana ihan samalla periaatteella:
def kulmain(a):
for i in range(0,len(a)):
a[i] = a[i]*360/(2*np.pi)
return a;
rad = [1,2,3,5,6]
kulmain(rad)
print(rad)
[57.29577951308232, 114.59155902616465, 171.88733853924697, 286.4788975654116, 343.77467707849394]
5. Satunnaisdatan luominen#
Kooste:
Satunnainen kokonaisluku \(\rightarrow\)
rand.randint(alin,ylin)
Satunnainen luku 0 ja 1 välillä \(\rightarrow\)
rand.random()
Mielivaltainen joukko mahdollisista \(\rightarrow\)
rand.choices(joukko, painotukset, k = määrä)
Mielivaltainen joukko populaatiosta \(\rightarrow\)
rand.sample(joukko, k = määrä)
Normaalijakauma \(\rightarrow\)
rand.normalvariate(odotusarvo, keskihajonta)
Tasainen lukujono \(\rightarrow\)
np.linspace(alku, loppu, num = jakojen lukumäärä)
Tasainen lukujono \(\rightarrow\)
np.arange(alku, loppu, askelkoko)
Joskus on kiinnostavaa luoda oikean datan kaveriksi simuloituja tai satunnaisia mittauksia. Siinä missä vaikkapa monimutkaisempien Monte Carlo -simulaatioiden tuottaminen meneekin tämän ohjeen tavoitteiden ulkopuolelle, voidaan silti vilkaista hieman erilaisia tapoja tuottaa satunnaisia numeroita. Tietokoneen tapauksessa on kuitenkin muistettava, että tavalliset satunnaisgeneraatiometodit ovat siinä mielessä pseudosatunnaisia deterministisiä prosesseja, ettei niitä kannata käyttää vaikkapa pankkisalaisuuksien tai turvalukujen kehittämiseen. Sitä varten on olemassa raskaampia ja monimutkaisempia keinoja.
# Luodaan satunnainen kokonaisluku halutulta väliltä.
lottoarpa = rand.randint(1,100)
teksti = 'Päivän voittoarpa on: '
print (teksti + repr(lottoarpa))
Päivän voittoarpa on: 20
# Luodaan satunnainen liukuluku 0 ja 1 väliltä kerrottuna viidellä.
luku = rand.random()*5
print (luku)
1.106541186311945
# Poimitaan satunnaisia jäseniä listalta, mutta tehdään tietyistä valinnoista todennäköisempiä.
nimiLapsille = ['Pekka','Jukka','Iida','Netta','Paula','Torsti']
todariPainot = [10,30,20,50,5,5]
# Määritetään montako nimeä halutaan, k = haluttu. Choices-komento voi ottaa saman tulokset useita kertoja.
nimet = rand.choices(nimiLapsille, weights = todariPainot, k = 3)
print(nimet)
['Jukka', 'Netta', 'Netta']
# Samanlainen valinta ilman toistoa.
oppilaat = ['Pekka','Jukka','Iida','Netta','Paula','Torsti']
kolmeVapaaehtoista = rand.sample(oppilaat, k = 3)
print (kolmeVapaaehtoista)
['Jukka', 'Iida', 'Torsti']
# Satunnaisluku annetusta normaalijakaumasta (odotusarvo, keskihajonta).
luku = rand.normalvariate(3, 0.1)
print (luku)
2.9905294642119853
# Luodaan tasaisesti jaettu lukusuora 1 ja 10 väliltä ja satunnaistetaan sitä hieman.
lukusuora = np.linspace(1, 10, 200)
def satunnaistin(a):
b = a.copy()
for i in range(0,len(b)):
b[i] = b[i]*rand.uniform(0,b[i])
return b;
tulos = satunnaistin(lukusuora)
# print(lukusuora)
# print(tulos)
fig = plt.figure(figsize=(15, 10))
plt.plot(tulos,'g*')
plt.show()
# Toinen tapa tuottaa tasaisesti jaettu lukujoukko [a,b[ komennolla arange(a,b,c) missä c on askeleen koko.
# Toiminto voi joskus häröillä jos c ei ole kokonaisluku. Huomaa, että b ei kuulu joukkoon.
luvut = np.arange(1,10,1)
print(luvut)
[1 2 3 4 5 6 7 8 9]
6. Kuvaajien piirtäminen#
Kooste:
Peruskuvaaja \(\rightarrow\)
plt.plot(nimi, 'tyyli ja väri', muotoiluja)
Hajotuskuva eli scatterplot \(\rightarrow\)
plt.scatter(x-data, y-data, marker = 'merkkityyli', color = 'väri', muotoiluja)
Histogrammi \(\rightarrow\)
plt.hist(nimi, jakojenMäärä, range = (alku, loppu), muotoiluja)
Selite näkyviin (vaatii muotoiluparametrit label = ‘nimike’) \(\rightarrow\)
plt.legend(muotoiluja)
Kuvaajat nätisti näkyviin samaan kuvaan \(\rightarrow\)
plt.show()
Normaalijakauman sovitus dataan \(\rightarrow\)
(mu, sigma) = norm.fit(nimi)
...
Kuvaajan muotoiluja ja nimeämistä \(\rightarrow\)
plt.xlabel('vaakanimi')
plt.title('otsikko')
fig = plt.figure(figsize=(vaakaluku, pystyluku))
Virheiden piirtämisestä \(\rightarrow\)
plt.errorbar(arvo1, arvo2, xerr = virhe1, yerr = virhe2, fmt = 'none')
Kuvaajat ovat kenties tärkein syy käyttää ohjelmointia tiedeopetuksessa. Isoistakin aineistoista on nopeaa ja vaivatonta tuottaa selkeyttäviä visualisaatioita. Kuhunkin tapaukseen sopii omanlaisensa metodi, joista yleisimpiä tarkastellaan tässä.
Kuvaajien värejä ja merkkejä voi vaihtaa vapaasti. Täällä on lista ymmärretyistä grafiikoista.
# Peruskuva plot-funktiolla. Jos parametreina toimii vain yksi tietorivi, x-akseli otetaan järjestysnumeroista.
lukuja = [1,3,54,45,52,34,4,1,2,3,2,4,132,12,12,21,12,12,21,34,2,8]
plt.plot(lukuja, 'b*')
# plt.show() on hyvä laittaa piirtojen loppuun. Kuvaajan saa näkyviin ilmankin, mutta joskus näkyviin tulisi pelkkä
# tiedostopaikka tai laskennallista sotkua. Tämä selkeyttää asioita, käytä sitä.
plt.show()
# Kuvaajille on kuitenkin hyvä antaa nimiä, jotta niiden lukijallekin on selvää mitä tapahtuu.
# Tässä näet miten eri osia voi nimetä.
# Kaksi satunnaista datasettiä.
tulos1 = np.linspace(10, 20, 50)*rand.randint(2,5)
tulos2 = np.linspace(10, 20, 50)*rand.randint(2,5)
# Piirretään molemmat.
plt.plot(tulos1, 'r^', label = 'Mittaus 1')
plt.plot(tulos2, 'b*', label = 'Mittaus 2')
# Nimetään akselit ja otsikot. Fontsize-parametrilla saa tekstit haluttuun kokoon.
plt.xlabel('Aika (s)', fontsize = 15)
plt.ylabel('Nopeus (m/s)', fontsize = 15)
plt.title('Liikkeen mittauksia \n', fontsize = 15) # \n luo uuden rivin otsikon muotoilua varten
# Lisätään selite. Jos loc-parametria ei määritellä, selite laitetaan automaattisesti johonkin mihin se mahtuu.
plt.legend(loc='upper left', fontsize = 15)
# Näytetään kuvaaja.
plt.show()
# Myös trigonometrisia funktioita voidaan piirtää nätisti.
# Tehdään x-akseliksi tasainen lukusuora.
x = np.linspace(0, 10, 100)
# Määritetään piirrettävät funktiot-
y1 = np.sin(x)
y2 = np.cos(x)
# Piirretään kuvaajat.
plt.plot(x, y1, color = 'b', label = 'sin(x)')
plt.plot(x, y2, color = 'g', label = 'cos(x)')
plt.legend()
plt.show()
# Kuvaajien oletuskoko Jupyterissa on jokseenkin pieni. figsize-komento auttaa skaalaamaan kuvia haluttuihin mittoihin.
# Toistetaan äskeinen kuvaaja.
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
# Tässä määrätään koko. Voit testata miten lukujen muokkaus vaikuttaa.
fig = plt.figure(figsize=(15, 10))
plt.plot(x, y1, color = 'b', label = 'sin(x)')
plt.plot(x, y2, color = 'g', label = 'cos(x)')
plt.legend()
plt.show()
Toinen perinteinen kuvaaja on arvopareja piirtävä scatterplot, jossa molemmat akselit ovat muuttujia. Hyvin yleinen esimerkiksi fysiikan tutkimuksessa.
def satunnaistin(a):
b = a.copy()
for i in range(0,len(b)):
b[i] = b[i]*rand.uniform(0,1)
return b;
# Otetaan satunnaista dataa, jossa toinen arvo jakautuu välillä 0-5 ja toinen 0-20.
arvo1 = satunnaistin(np.linspace(3,5,100))
arvo2 = satunnaistin(np.linspace(10,20,100))
fig = plt.figure(figsize=(10,5))
plt.scatter(arvo1, arvo2, marker ='*', color = 'b')
plt.show()
# Toinen scatter-esimerkki, jossa molemmat arvot
# hajoavat normaalijakauman mukaan odotetusta lineaarisesta riippuvuudesta.
def satunnaistaja(a):
b = a.copy()
for i in range(0,len(b)):
b[i] = b[i]*rand.normalvariate(1, 0.1)
return b;
arvo1 = satunnaistaja(np.linspace(3,5,100))
arvo2 = satunnaistaja(np.linspace(10,20,100))
fig = plt.figure(figsize=(10,5))
plt.scatter(arvo1, arvo2, marker ='*', color = 'b', label = 'Mittaukset')
# Lasketaan huvikseen mukaan myös suoran sovite pienimmällä neliösummalla.
slope, intercept, r_value, p_value, std_err = stats.linregress(arvo1, arvo2)
plt.plot(arvo1, intercept + slope*arvo1, 'r', label='Sovitus')
plt.legend(fontsize = 15)
plt.show()
# Jos haluaisi tietää suoran matemaattisia arvoja, voisi kirjoittaa esim. print (slope) jne.
Yksi merkittävä kuvaajatyyppi on histogrammi, jolla voidaan kuvata eri tulosten suhteellista esiintyvyyttä datassa. Histogrammeja näkee hyvin monissa paikoissa, niin hiukkasfysiikassa, lääketieteessä kuin yhteiskunnallisissakin tiedoissa.
# Otetaan satunnainen ikäjakauma ja luodaan sitä kuvaava histogrammi.
def ikageneraattori(a):
b = a.copy()
for i in range(0, len(b)):
b[i] = b[i]*rand.randint(1,100)
return b;
iat = ikageneraattori(np.ones(1000))
fig = plt.figure(figsize = (10,5))
plt.hist(iat, bins = 100, range = (0,110))
plt.xlabel('Ikävuodet', fontsize = 15)
plt.ylabel('Määrä', fontsize = 15)
plt.title('Ikäjakauma %i ihmisen otoksessa \n' %(len(iat)), fontsize = 15 )
plt.show()
# Otetaan hiukkasdataa törmäyksistä, joista havaittiin tulevan myonipareja.
kaksoismyonit = pd.read_csv('http://opendata.cern.ch/record/545/files/Dimuon_DoubleMu.csv')
# Piirretään koko roskan histogrammi invariantin massan, sarake M, suhteen.
fig = plt.figure(figsize = (10,5))
plt.hist(kaksoismyonit.M, bins = 300, range = (0,150))
plt.xlabel('Invariantti massa (GeV/$c^2$)', fontsize = 15)
plt.ylabel('Tapahtumien lukumäärä', fontsize = 15)
plt.title('Invariantin massan jakauma myoneista laskettuna \n', fontsize = 15 )
plt.show()
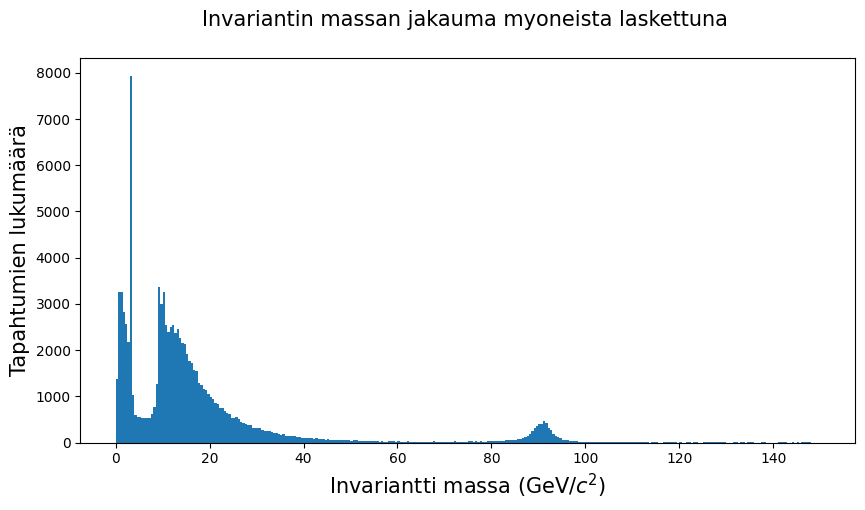
# Tarkastellaan ylläolevasta vain 80 ja 100 välillä olevaa aluetta. Tähän kävisi myös range-parametrin siirto,
# mutta on kevyempää rajata pienempi pala dataa käsittelyyn.
huippu = kaksoismyonit[(kaksoismyonit.M >= 80) & (kaksoismyonit.M <= 100)]
fig = plt.figure(figsize = (10,5))
plt.hist(huippu.M, bins = 200, range = (80,100))
plt.xlabel('Invariantti massa (GeV/$c^2$)', fontsize = 15)
plt.ylabel('Tapahtumien lukumäärä', fontsize = 15)
plt.title('Invariantin massan jakauma myoneista laskettuna \n', fontsize = 15 )
plt.show()
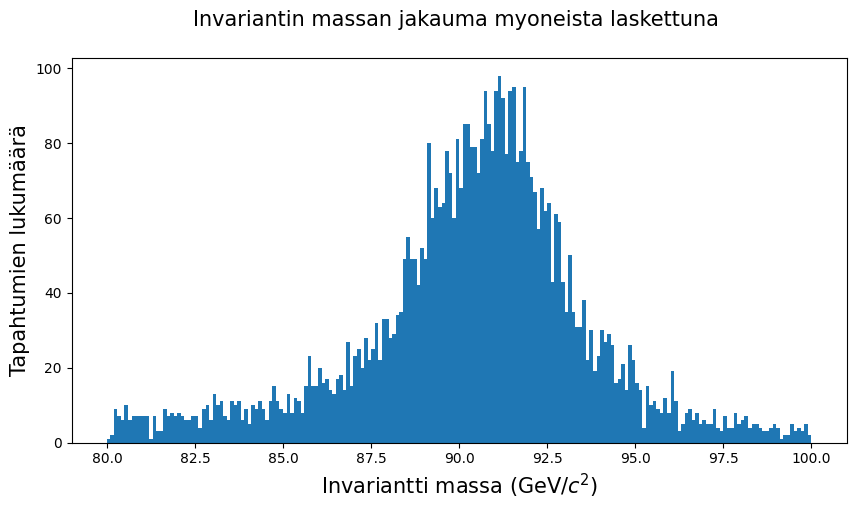
Keskimäärin epälineaaristen käyrien sovittaminen tuloksiin vaatii hieman enemmän koodaamista, mutta jakaumien tapauksessa Pythonista löytyy aika kattavasti valmiita komentoja. Ylläolevaan kuvaajaan saa esimerkiksi kivan normaalijakauman sovitteen:
# Tässä määritellään sovituksen rajat. Nämä on hyvä määritellä tässä, jotta itse koodiin ei tarvitse porautua
# jälkeenpäin ja etsiä jokaista viittauskohtaa erikseen.
alaraja = 87
ylaraja = 95
pala = kaksoismyonit[(kaksoismyonit.M > alaraja) & (kaksoismyonit.M < ylaraja)]
fig = plt.figure(figsize=(15, 10))
# Tässä määritellään miltä väliltä alkuperäistä dataa katsellaan. Sovitteen ei tarvitse seurata sitä vaan
# se on suunniteltu pelkän huipun kohdalle.
esite_ala = 80
esite_yla = 100
alue = kaksoismyonit[(kaksoismyonit.M > esite_ala) & (kaksoismyonit.M < esite_yla)]
# Koska näytetyn histogrammin pinta-ala asetetaan ykköseen kertymäfunktiota varten, määritellään tässä kerroin
# joka huomioi tarkastellun alueen ja koko alueen suhteen sovitusta tehtäessä.
kerroin = len(pala)/len(alue)
(mu, sigma) = norm.fit(pala.M)
# Tässä piirretään itse histogrammi valituissa rajoissa koko alkuperäisestä datasta..
n, bins, patches = plt.hist(kaksoismyonit.M, 300, density = 1, facecolor = 'green', alpha=0.75, histtype='stepfilled',
range=(esite_ala,esite_yla))
# Tässä piirretään normaalijakauman funktio aiemman kertoimen kera.
y = kerroin*norm.pdf( bins, mu, sigma)
l = plt.plot(bins, y, 'r--', linewidth=2)
plt.xlabel('Massa [GeV/$c^2$]',fontsize=15)
plt.ylabel('Tapahtuman todennäköisyys', fontsize=15)
# Tämä otsikko näyttää hieman karulta, mutta se huomioi nyt datasta lasketut tilastolliset arvot.
plt.title(r'$\mathrm{Histogrammi\ invarianteista\ massoista\ normeerattuna\ ykköseen:}\ \mu=%.3f,\ \sigma=%.3f$'
%(mu,sigma),fontsize=15)
# Tähän saa myös ruudukon, huraa!
plt.grid(True)
plt.show()
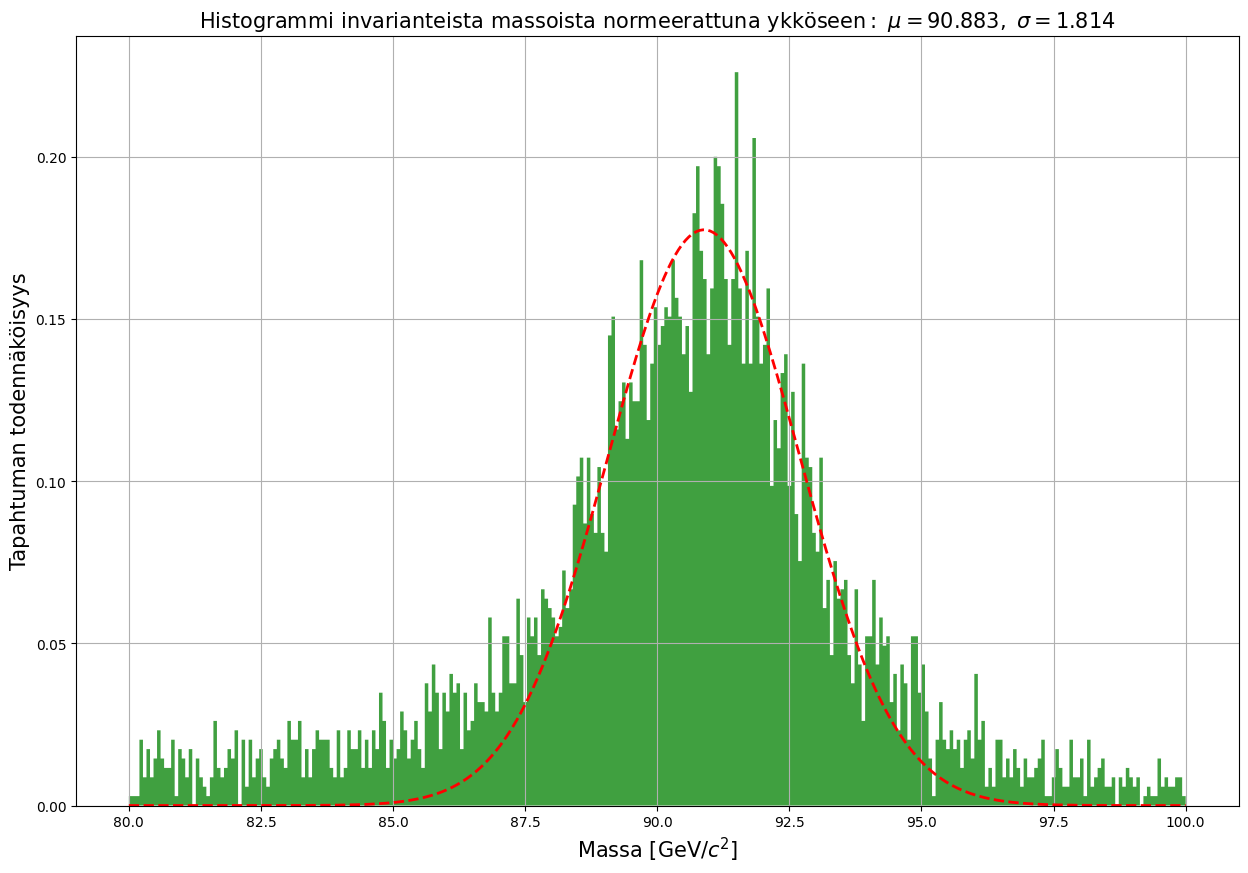
Kuvaajan voi piirtää myös tiedostosta, jossa ei ole numeroita. Otetaan esimerkiksi tilastoja Lontoon liikenneonnettomuuksista.
# Nelisenkymmentätuhatta tapaturmaa erinäisin kulkupelein, samalla tapahtumalla on sama viitenumero AREFNO.
liikenne = pd.read_table('../Data/2016-gla-data-extract-vehicle.csv', sep = ",")
loukkaantuneet = pd.read_table('../Data/2016-gla-data-extract-casualty.csv', sep = ",")
liikenne.head()
| AREFNO | Borough | Boro | Easting | Northing | Vehicle Ref. | Vehicle Type | Vehicle Type (Banded) | Vehicle Manoeuvres | Vehicle Skidding | ... | Junction Location | Object in C/W | Veh. Leaving C/W | Veh. off C/W | Veh. Impact | VJNYPURP DECODED | Driver Sex | Driver Age | Driver Age (Banded) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1160001090 | CITY OF LONDON | 0 | 531350 | 181580 | 1 | 08 Taxi | 4 Taxi | 04 Slowing Or Stopping | 0 No Skidding/Overturn | ... | 0 Not At Jct | 00 None | 0 Did Not Leave | 00 None | 4 N/S Hit First | 1 Jny Part of Work | 1 Male | 46 | 35-64 | |
| 1 | 1160002980 | CITY OF LONDON | 0 | 532780 | 180410 | 1 | 01 Pedal Cycle | 1 Pedal cycle | 13 Overtake Move Veh O/S | 0 No Skidding/Overturn | ... | 0 Not At Jct | 00 None | 0 Did Not Leave | 00 None | 1 Front Hit First | 5 Other/Not Known | 3 Not Traced | 0 | Unknown | |
| 2 | 1160002980 | CITY OF LONDON | 0 | 532780 | 180410 | 2 | 01 Pedal Cycle | 1 Pedal cycle | 14 Overtake Stat Veh O/S | 0 No Skidding/Overturn | ... | 0 Not At Jct | 00 None | 0 Did Not Leave | 00 None | 2 Back Hit First | 5 Other/Not Known | 1 Male | 46 | 35-64 | |
| 3 | 1160006347 | CITY OF LONDON | 0 | 531400 | 181570 | 1 | 09 Car | 3 Car | 09 Turning Right | 0 No Skidding/Overturn | ... | 8 Jct Mid | 00 None | 0 Did Not Leave | 00 None | 1 Front Hit First | 5 Other/Not Known | 1 Male | 22 | 17-24 | |
| 4 | 1160006347 | CITY OF LONDON | 0 | 531400 | 181570 | 2 | 09 Car | 3 Car | 05 Moving Off | 0 No Skidding/Overturn | ... | 8 Jct Mid | 00 None | 0 Did Not Leave | 00 None | 3 O/S Hit First | 5 Other/Not Known | 1 Male | 69 | 65+ |
5 rows × 21 columns
loukkaantuneet.head()
| AREFNO | Borough | Boro | Easting | Northing | CREFNO | Casualty Class | Casualty Sex | Casualty Age (Banded) | Casualty Age | No. of Casualties | Casualty Severity | Ped. Location | Ped. Movement | Mode of Travel | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1160001090 | CITY OF LONDON | 0 | 531350 | 181580 | 1 | 3 Pedestrian | 1 Male | 25-59 | 54 | 1 | 3 Slight | 09 In Road - Not Crossing | 7 In Rd Facing Traffic | 1 Pedestrian | |
| 1 | 1160002980 | CITY OF LONDON | 0 | 532780 | 180410 | 1 | 1 Driver/Rider | 1 Male | 25-59 | 46 | 1 | 2 Serious | -2 Unknown | -2 N/A | 2 Pedal Cycle | |
| 2 | 1160006347 | CITY OF LONDON | 0 | 531400 | 181570 | 3 | 2 Passenger | 2 Female | 60+ | 61 | 1 | 3 Slight | -2 Unknown | -2 N/A | 4 Car | |
| 3 | 1160006347 | CITY OF LONDON | 0 | 531400 | 181570 | 2 | 1 Driver/Rider | 1 Male | 60+ | 69 | 1 | 3 Slight | -2 Unknown | -2 N/A | 4 Car | |
| 4 | 1160006347 | CITY OF LONDON | 0 | 531400 | 181570 | 1 | 1 Driver/Rider | 1 Male | 16-24 | 22 | 1 | 3 Slight | -2 Unknown | -2 N/A | 4 Car |
# Erotellaan datasta ikähaarukka, jota tarkastellaan.
alaraja = 16
ylaraja = 25
ikahaarukka = liikenne.loc[(liikenne['Driver Age'] <= ylaraja) & (liikenne['Driver Age'] >= alaraja)]
# Tehdään kuvaaja tämän ikäryhmän onnettomuuksista eri välineillä.
fig = plt.figure(figsize = (10,5))
plt.hist(ikahaarukka['Vehicle Type'], bins = 50)
# Määritetään tässä miten vaaka-akselin selitteet toimivat. Erityisesti miten ne kallistuvat.
plt.xticks(rotation = 40, ha = 'right')
plt.show()
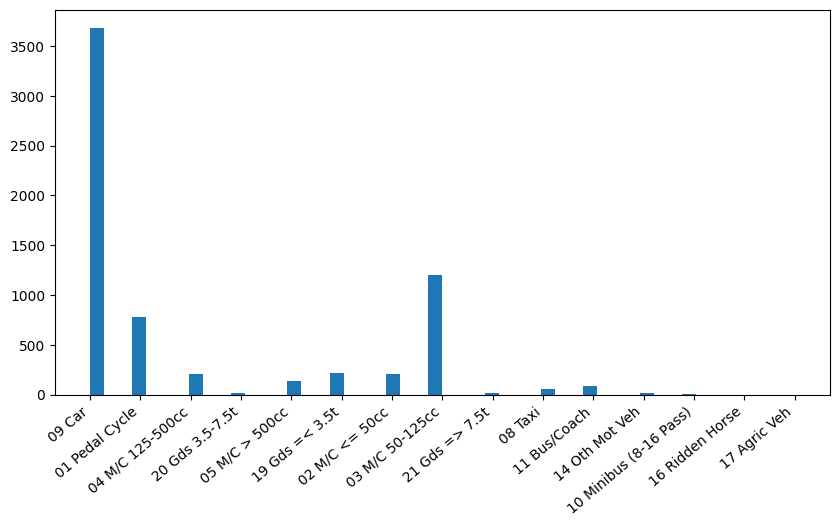
Kuvaajasta nähdään, että suurin osa liikenneonnettomuuksista on väemmän yllättäen autojen törmäilyä. Pieni yllätys voi kuitenkin tulla siitä, että listassa näkyy myös ratsuhevonen. Tätä voisi lähteä tarkastelemaan syvemminkin, esimerkiksi seuraavasti:
# Erotellaan hevostörmäykset liikennedatasta.
hepat = liikenne.loc[liikenne['Vehicle Type'] == '16 Ridden Horse']
hepat.head()
| AREFNO | Borough | Boro | Easting | Northing | Vehicle Ref. | Vehicle Type | Vehicle Type (Banded) | Vehicle Manoeuvres | Vehicle Skidding | ... | Junction Location | Object in C/W | Veh. Leaving C/W | Veh. off C/W | Veh. Impact | VJNYPURP DECODED | Driver Sex | Driver Age | Driver Age (Banded) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 33056 | 0116TW60237 | RICHMOND-UPON-THAMES | 24 | 518450 | 173770 | 1 | 16 Ridden Horse | 8 Other | 18 Going Ahead Other | 0 No Skidding/Overturn | ... | 2 Jct Cleared | 00 None | 0 Did Not Leave | 00 None | 1 Front Hit First | 1 Jny Part of Work | 1 Male | 25 | 25-34 | |
| 33057 | 0116TW60237 | RICHMOND-UPON-THAMES | 24 | 518450 | 173770 | 2 | 16 Ridden Horse | 8 Other | 18 Going Ahead Other | 0 No Skidding/Overturn | ... | 2 Jct Cleared | 00 None | 0 Did Not Leave | 00 None | 2 Back Hit First | 1 Jny Part of Work | 1 Male | 28 | 25-34 |
2 rows × 21 columns
# Jaha, sama AREFNO, eli hepat ajoivat toistensa perään. Mites vakavaa vammaa tuli?
heppaVammat = loukkaantuneet.loc[loukkaantuneet['AREFNO'] == '0116TW60237']
heppaVammat.head()
# Protip: jos haluaa olla helppo suuren datan kanssa, manuaalisen numeronsyötön sijaan tuohon laitettaisiin
# viite alkuperäisen taulukon heppaosasta kaivetun solun mukaan ja koko prosessi tapahtuisi automaattisesti.
# Kannattaa kokeilla oman akateemisen mielenkiinnon vuoksi kokeilla.
| AREFNO | Borough | Boro | Easting | Northing | CREFNO | Casualty Class | Casualty Sex | Casualty Age (Banded) | Casualty Age | No. of Casualties | Casualty Severity | Ped. Location | Ped. Movement | Mode of Travel | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 22096 | 0116TW60237 | RICHMOND-UPON-THAMES | 24 | 518450 | 173770 | 1 | 1 Driver/Rider | 1 Male | 25-59 | 28 | 1 | 3 Slight | -2 Unknown | -2 N/A | 8 Other Vehicle |
Kuvaajien piirtoon liittyen vielä sananen virheistä. Oikeissa mittauksissa on aina heiluntaa sen suhteen, mikä on tarkka tulos ja miten tarkasti jotain edes voidaan mitata. Nämä tarkkuusarvot voidaan kaivaa tilastollisilla prosesseilla tuloksiin tehdyistä sovitteista tai voi olla että ne ovat tiedossa jokaisen mittapisteen kohdalla erikseen, kuten vaikkapa koulussa tehtävien kokeiden kanssa voisi käydä (mikäli virheeseen ehditään paneutua). Tehdään esimerkki tällaisesta.
def satunnaistaja(a):
b = a.copy()
for i in range(0,len(b)):
b[i] = b[i]*rand.normalvariate(1, 0.1)
return b;
# Luodaan mittapisteet normaalijakautuneesti heiluen.
arvo1 = satunnaistaja(np.linspace(3,5,100))
arvo2 = satunnaistaja(np.linspace(10,20,100))
# Annetaan kullekin mittapisteelle normaalijakautunut satunnainen virhe.
virhe1 = (1/5)*satunnaistaja(np.ones(len(arvo1)))
virhe2 = satunnaistaja(np.ones(len(arvo2)))
fig = plt.figure(figsize=(10,5))
plt.scatter(arvo1, arvo2, marker ='*', color = 'b', label = 'Mittaukset')
plt.errorbar(arvo1, arvo2, xerr = virhe1, yerr = virhe2, fmt = 'none')
# Lasketaan huvikseen mukaan myös suoran sovite pienimmällä neliösummalla.
slope, intercept, r_value, p_value, std_err = stats.linregress(arvo1, arvo2)
plt.plot(arvo1, intercept + slope*arvo1, 'r', label='Sovitus')
plt.legend(fontsize = 15)
plt.show()
# Jos haluaisi tietää suoran matemaattisia arvoja, voisi kirjoittaa esim. print (slope) jne.
7. Animaatioiden tekeminen#
Pythonilla voi tehdä animaatioita monella tavalla. Emme kuitenkaan suosittele plotly-paketin käyttöä Notebookien kanssa, sillä se on niin hidasta ettei mistään tule mitään. Tehdään tässä esimerkki, joka näyttää kivasti miksi enemmän dataa antaa parempia tuloksia.
data = pd.read_csv('http://opendata.cern.ch/record/545/files/Dimuon_DoubleMu.csv')
iMass = data.M
# Määritetään funktio, joka tuottaa kuvamme. Num kertoo monennessako askeleessa mennään ja funktio piirtää joka
# askeleelle uuden histogrammin.
def updt_hist(num, iMass):
plt.cla()
axes = plt.gca()
axes.set_ylim(0,8000)
axes.set_xlim(0,200)
plt.hist(iMass[:num*480], bins = 120)
Huom: animaatioita sisältävät solut ovat hitaita. Mitä enemmän kuvia, sitä hitaampaa niiden tekeminen on. Tämä voi viedä useita minuutteja.
# Tuodaan animaatioita tuottava paketti.
import matplotlib.animation
%%capture
# (Toimii MyBinderissa) Capture-magic on tässä estämässä tätä solua tuottamasta suoraan näkyvää tulosta, jottei outputista puske
# omituisia tyhjiä kuvia tai muuta turhaa. Se siisteyttää elämää.
fig = plt.figure()
# fargs kertoo mitä muuttujia funktio ottaa sisäänsä ja tyhjä kohta kertoo ohjelmalle, että sen on käytettävä
# kahta muuttujaa. Toiseksi otetaan senhetkinen ruutu.
anim = matplotlib.animation.FuncAnimation(fig, updt_hist, frames = 200, fargs=(iMass, ) )
# anim.to_jshtml() muuttaa animaation (javascript)html:ksi, jolloin Notebook osaa näyttää sen.
from IPython.display import HTML
HTML(anim.to_jshtml())
# Tämän ajamalla animaatio saadaan sitten näkyväksi, kun se on ohjelman muistissa.
HTML(anim.to_jshtml())
8. Kartat ja lämpökartat#
Interaktiivisia karttoja joihin voi piirtää dataa Notebookeilla? Kyllä kiitos!
Tällaisten tekeminen on helpompaa kuin voisi kuvitella. Tässä esimerkissä nähdään, miten homma toimii kun saatavilla on jotain dataa, joka sisältää leveys- ja pituuspiirikoordinaatteja.
# Folium-paketista löydämme karttapohjia.
import folium
# Tiheyttä värein edustava heatmap-systeemi on myös näppärä, joten otetaan se käyttöön.
from folium.plugins import HeatMap
# Tässä datassa on jatkuvasti päivittyvät tiedot maanjäristyksistä eri puolella planeettaa viimeisen
# kuukauden ajalta. Siellä voi olla jo tämäkin päivä.
quakeData = pd.read_csv('https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/all_month.csv')
quakeData.head()
# Koska datamme on DataFrame-muodossa, muutamme sen ensin listoiksi, joita HeatMap ymmärtää.
# Tehdään tarpeeksi pitkä lista, johon voimme tallentaa haluamiamme arvoja.
dat = [0]*len(quakeData)
# Listaan tulee arvoja (tuples), jotka sisältävät leveyspiirin, pituuspiirin ja järistyksen voimakkuuden.
# Magnitudia ei sinänsä tarvittaisi, mutta se on mukava olla siellä vaikkapa siltä varalta, että haluaa tarkastella
# vain tietyn rajan ylittäviä tapauksia.
for i in range(0, len(quakeData)):
dat[i] = [quakeData['latitude'][i], quakeData['longitude'][i], quakeData['mag'][i]]
# Siltä varalta, että tiedoissa on mukana sellaisia rivejä, joiden magnitudia ei tiedetä (listattu NaN:ina),
# poistetaan ne ettei listamme ala käyttäytymään hankalasti.
dat = [x for x in dat if ~np.isnan(x[2])]
# Erilaisia karttatyylejä: https://deparkes.co.uk/2016/06/10/folium-map-tiles/
# world_copy_jump = True mahdollistaa kartan rullauksen sivulle niin, että asiat näkyvät yhä.
# Jos haluat vain yhden karttalevityksen, lisää argumentti no_wrap = True sulkuihin.
# Argumentti control_scale lisää karttaan mittakaavan.
m = folium.Map([15., -75.], tiles='openstreetmap', zoom_start=3, world_copy_jump = True, control_scale = True)
HeatMap(dat, radius = 15).add_to(m)
m
9. Ongelmia? Katso tänne#
Kooste:
Yhyy, en osaa?
Solu jäi jumiin eikä piirrä kuvaajaani tai aja koodiani?
Virheilmoitus herjaa ‘nimi is not defined’ tai ‘nimi does not exist’?
Yritän tallentaa muuttujaan asioita, mutta print(nimi) kertookin None?
Datani ei suostu lataamaan?
Lataamassani datassa on jotain omituisia ‘NaN’-arvoja?
Yhdistin palasia datasta, mutta nyt en enää pysty tekemään asioita uudella muuttujallani?
Koodini ei toimi, vaikka se on ihan varmasti oikein kirjoitettu?
Datan päivämäärät sekoittavat toiminnan, miten korjaan?
Kopioin datan uuteen muuttujaan, jonka käsittelyn jälkeen huomaan alkuperäisen muuttujan arvojen vaihtuneen?
Yhyy, en osaa?#
Nou hätä, kukaan ei aloita mestarina. Tekemällä oppii ja virheet kuuluvat asiaan.
Pythonissa on kivana puolena sen laaja käyttäjäkunta: mitä ikinä keksitkään kysyä, et ole ensimmäinen ja vastaus luultavasti löytyy ensimmäisten googlaustulosten joukosta. Tässä on ohjeita muutamiin yleisimpiin ongelmatilanteisiin.
Solu jäi jumiin eikä piirrä kuvaajaani tai aja koodiani?#
Jos solun ajamisessa kuluu joitain sekunteja pidempään ilman, että sen pitäisi tehdä mitään erityisen raskasta, on mahdollista että koodissa on virheellisesti kirjoitettu jokin silmukka johon koneen lukija jää jumiin. Pysäytä kernelin toiminta ja tarkista koodisi mahdollisten kitkakohtien varalta. Jos et löydä ongelmaa, yksinkertaista syntaksia kunnes olet varma, että palaset etenevät loogisesti haluttuun suuntaan.
Yksi yleinen ongelma on, että syntaksivirhe ajaa koneen tekemään jotain väärää. Esimerkkitapaus: piirrät histogrammia yhdestä isomman datan sarakkeesta, mutta unohdat sarakkeen nimen koodista. Tällöin kone yrittää toteuttaa käskyäsi ja hämmentyy saamastaan koko datan sisältävästä taulukosta. Pysäytä kernelin toiminta ja korjaa muuttujien nimet oikein.
Virheilmoitus herjaa ‘nimi is not defined’ tai ‘nimi does not exist’?#
Muuttujaa, johon viittaat, ei ole olemassa. Olethan muistanut varmasti ajaa tässä istunnossa sen solun, jossa kyseinen muuttuja määritellään? Muista myös kirjainkoon tarkka merkitys.
Yritän tallentaa muuttujaan asioita, mutta print(nimi) kertookin None?#
Tallennuksessasi on jokin ongelma. Muista aina tallentaa tekemäsi operaatiot muuttuujaan, eli esimerkiksi
muuttuja = ... lataus datasta
muuttuja = muuttuja*2
eikä
muuttuja = ... lataus datasta
muuttuja*2
Jos muuttujan tarkasteleminen palauttaa None, tällöin muuttujasi on tyhjä. Tarkasta, että haluamasi operaatio oikeasti on tehtävissä oleva eikä hajoa vaikkapa jonkin sisäfunktion vääriin syötteisiin.
Datani ei suostu lataamaan?#
Tavallisia csv- ja vastaavia tekstitiedostoja voi tarkastella tekstinkäsittelyohjelmilla. Tällöin näet, millä merkillä arvot on eroteltu, miltä riviltä relevantti data alkaa tai onko tiedoston sisältö ylipäätään se mitä kuvittelit.
Jakomerkit, otsikkorivit ja vastaavat voit määrittää lukufunktion parametreina, esimerkiksi
pd.read_csv('linkki tiedostoon', sep = ';')
avaisi puolipisteellä erotetun csv:n. Lisää ylempänä dataa käsittelevässä kappaleessa 3.
pd.read_table() voi auttaa selvittämään datan luonnetta jos ei jaksa avata tekstieditoria.
Joskus ongelma johtuu merkistöjä ohjaavien koodien yhteensopimattomuudesta. Tällöin parametri encoding voi auttaa. Näistä löydät enemmän täältä. Jos oletusasetus ei toimi, usein jokin ISO-variantti kelpaa.
Lataamassani datassa on jotain omituisia ‘NaN’-arvoja?#
NaN, ‘Not a Number’, kertoo että tässä kohtaa dataa ei ole ymmärrettävää arvoa. Joko arvo on omituinen (kuten negatiivisen luvun neliöjuuri) tai sitä ei vain ole.
Monet funktiot eivät välitä NaN-arvoista tai niiden parametreihin voi laittaa asetuksen, jolla ne eivät huomioi niiden olemassaoloa. Tämä helpottaa etenkin isojen datojen läpikäyntiä, kun kaikkia mahdollisia virheitä ei huomioida eikä kone jumitu törmätessään matemaattiseen mahdottomuuteen.
Yhdistin palasia datasta, mutta nyt en enää pysty tekemään asioita uudella muuttujallani?#
Yhdistitkö eri tyyppisiä muuttujia? Kokonaisluvut (integer) ovat tietokoneelle erilaisia kuin desimaaleja ymmärtävät liukuluvut (float), jotka ovat erilaisia kuin teksti (string) ja niin edelleen. Joskus numerosarjakin voi olla kirjoitettu johonkin dataan stringinä, mikä on kovasti epämukavaa huomata jälkikäteen. Pythonissa on erilaisia vertailukomentoja, kuten isstring, joilla voi tarkistaa muuttujien tyypin.
Yhdistithän palaset oikeisiin suuntiin? Jos halusit sarakkeet vierekkäin, niitä ei kannata vahingossa liittää peräkkäin yhdeksi pitkäksi sarakkeeksi. Tiedoston tarkastelu vaikkapa len(nimi) ja nimi.head() komennoilla on usein hyödyllistä näissä tilanteissa.
Koodini ei toimi, vaikka se on ihan varmasti oikein kirjoitettu?#
Tarkista nyt kuitenkin, ettei ole piste väärässä kohdassa tai väärä kirjainkoko jossakin.
Jos koodi ei ihan oikeasti vaan toimi vaikka pitäisi, syy voi löytyä kerneliin jääneistä aiemmista tiedoista muistissa. Näissä tapauksissa voi välillä vain kokeilla Kernel-valikosta Restart & Clear Outputtia ja uudelleen ajamista vaikka parikin kertaa.
Datan päivämäärät sekoittavat toiminnan, miten korjaan?#
Päivämäärät saattavat tulla ilmoitettuina monessa muodossa. Jos oletusasetukset eivät saa dataa toimimaan nätisti, pd.read_csv():n dokumentaatiosta näkyy millä sen parametreilla voi vaikuttaa päivämäärien tulkintaan. Esim. dayfirst tai date_parser saattavat ratkaista ongelman. Pythonissa on myös paketti time, josta löytyy varmasti sopivat palat tilanteeseen.
Kopioin datan uuteen muuttujaan, jonka käsittelyn jälkeen huomaan alkuperäisen muuttujan arvojen vaihtuneen?#
Python operoi osoittimilla, joissa muuttujaan tallentuu oikeastaan tiedon itsensä sijaan paikkatieto siitä, mistä päin muistia kyseinen tieto löytyy. Kopioitaessa kokonaista datamuuttujaa toiseen muuttujaan yksittäisten rivien tai sarakkeiden sijaan saattaa käydä niin, että siinä ei oikeastaan tehdä muuta kuin viitataan vanhaan tietoon. Jos uudelle muuttujalle tehdään muutoksia, tällöin osoittimet vievät muutokset myös vanhaan dataan ja puf, sekin on muuttunut. Tätä sattuu joskus ja se on hitusen rasittavaa. Olemme huomanneet hyväksi kopioida alkuperäisen:
uusiNimi = vanhaNimi.copy()
jolloin oikeasti tehdään uutta tietoa muistiin niin, ettei viittaus vahingossakaan tapahdu alkuperäiseen muuttujaan. Kiinnostavaa kyllä tätä ongelmaa ei tunnu esiintyvän muussa kuin koko datan kerralla siirtämisen yhteydessä, eli yksittäisten rivien erottelu uusiin muuttujiin tapahtuu ilman mitään viittausta alkuperäistietoihin.